Previously we discussed 7 effective methods for blocking email spam with Postfix on CentOS/RHEL. In this tutorial, we are going to learn how to use SpamAssassin (SA) to detect spam on CentOS/RHEL mail server. SpamAssassin is a free, open-source, flexible and powerful spam-fighting tool.
SpamAssassin is a score-based system. It will check email message against a large set of rules. Each rule adds or removes points in the message’s score. If the score is high enough (by default 5.0), the message is considered spam.

Install SpamAssassin on CentOS/RHEL
Run the following command to install SpamAssassin from the default CentOS/RHEL software repository.
sudo dnf install spamassassin
The server binary installed by the spamassassin package is called spamd, which will be listening on TCP port 783 on localhost. Spamc is the client for SpamAssassin spam filtering daemon. By default, the spamassassin systemd service is disabled, you can enable auto start at boot time with:
sudo systemctl enable spamassassin
Then start SpamAssassin.
sudo systemctl start spamassassin
Integrate SpamAssassin with Postfix SMTP Server as a Milter
There are several ways you can use to integrate SpamAssassin with Postfix. I prefer to use SpamAssassin via the sendmail milter interface, because it allows me to reject an email when it gets a very high score such as 8, so it will never be seen by the recipient.
Install the spamass-filter packages on CentOS/RHEL from the EPEL software repository.
sudo dnf install epel-release sudo dnf install spamass-milter
Start the service.
sudo systemctl start spamass-milter
Enable auto-start at boot time.
sudo systemctl enable spamass-milter
Next, edit /etc/postfix/main.cf file and add the following lines at the end of the file.
# Milter configuration milter_default_action = accept milter_protocol = 6 smtpd_milters = unix:/run/spamass-milter/spamass-milter.sock non_smtpd_milters = $smtpd_milters
If you have configured OpenDKIM and OpenDMARC on CentOS/RHEL, then these lines should look like below. The milter order matters.
# Milter configuration milter_default_action = accept milter_protocol = 6 smtpd_milters = inet:127.0.0.1:8891,inet:127.0.0.1:8893,unix:/run/spamass-milter/spamass-milter.sock non_smtpd_milters = $smtpd_milters
If you haven’t configured OpenDMARC, then you should remove local:opendmarc/opendmarc.sock, from smtpd_milters.
Save and close the file. Now open the /etc/sysconfig/spamass-milter file and find the following line.
#EXTRA_FLAGS="-m -r 15"
Uncomment this line and change 15 to your preferred reject score such as 8.
EXTRA_FLAGS="-m -r 8"
If the score of a particular email is over 8, Spamassassin would reject it and you would find a message like below in the /var/log/maillog file, indicating it’s rejected.
milter-reject: END-OF-MESSAGE 5.7.1 Blocked by SpamAssassin
If you want the sender to see a different reject text, then add the -R (reject text) option like below.
EXTRA_FLAGS="-m -r 8 -R SPAM_ARE_NOT_ALLOWED_HERE"
It’s a good practice to ignore emails originating from localhost by adding the -i 127.0.0.1 option.
EXTRA_FLAGS="-m -r 8 -R SPAM_ARE_NOT_ALLOWED_HERE -i 127.0.0.1"
We also need to add the -g sa-milt option to make the spamass-milter socket writable by the sa-milt group.
EXTRA_FLAGS="-m -r 8 -R SPAM_ARE_NOT_ALLOWED_HERE -i 127.0.0.1 -g sa-milt"
Save and close the file. Then add postfix user to the sa-milt group, so that Postfix will be able to communicate with spamass-milter.
sudo gpasswd -a postfix sa-milt
Restart Postfix and Spamass Milter for the changes to take effect.
sudo systemctl restart postfix spamass-milter
Check the status and make sure they are running.
sudo systemctl status postfix spamass-milter
Checking Email Header and Body with SpamAssassin
SpamAssassin ships with many spam detection rules in /usr/share/spamassassin/ directory. Allow me to explain some of the rules.
In the /usr/share/spamassassin/20_head_tests.cf file, you can find the following two lines.
header MISSING_HEADERS eval:check_for_missing_to_header() describe MISSING_HEADERS Missing To: header
The first line tests if the To: header exists in an email message. The second line, which is optional, explains what the first line does. The uppercase letters is the name of this test.
The following 3 lines are for testing if there’s a Date: header in the email message.
header __HAS_DATE exists:Date meta MISSING_DATE !__HAS_DATE describe MISSING_DATE Missing Date: header
And these 3 lines are for testing if there’s a From: header in the email message.
header __HAS_FROM exists:From meta MISSING_FROM !__HAS_FROM describe MISSING_FROM Missing From: header
Set Custom Score for Existing Rules
In the 50_scores.cf and 72_scores.cf file, you can see the default scores for various tests. If you think the default score is too low or too high for a certain test, you can set custom score in /etc/mail/spamassassin/local.cf file.
sudo nano /etc/mail/spamassassin/local.cf
For example, RFC 5322 requires that every email message must have From: and Date: header fields, so I can set a very high score if either of them is missing in an email message by appending the following two lines in local.cf file.
score MISSING_FROM 5.0 score MISSING_DATE 5.0
Although the To: header field is not mandatory in RFC 5322, I prefer to set a high score if it’s missing in an email message because I have never seen a legitimate email missing this header field.
score MISSING_HEADERS 3.0
Some spammers uses two email addresses in the From: header field like below.
From: "tonywei_darefly_mold@aliyun.com" <sales10@darefly-mould.com>
I think the default score for this kind of email is low, I prefer to set it to 3.0.
score PDS_FROM_2_EMAILS 3.0
There are spammers who send empty message with no subject and no textual parts in the body. I set the score for this kind of email to 5.0, so it will be placed to spam folder. Why read it if it’s empty?
score EMPTY_MESSAGE 5.0
And other spammers often ask you to send a read receipt, I set the score to 2.0 for this kind of email.
score FREEMAIL_DISPTO 2.0
There are some spammers use different domain names in the From: and Reply-To: header, I give them a 3.5 score.
score FREEMAIL_FORGED_REPLYTO 3.5
I also have seen some spammers using non-existent domain name in the From: header field. I set a 5.0 score for this type of email.
score DKIM_ADSP_NXDOMAIN 5.0
Last but not least, many spammers spoof the gmail.com domain in the From: header field. I set a 2.5 score this kind of email.
score FORGED_GMAIL_RCVD 2.5
Adding Your Own Rules
You can add custom SpamAssassin rules in /etc/mail/spamassassin/local.cf file.
sudo nano /etc/mail/spamassassin/local.cf
Header Rules
For example, some spammers use the same email address in the From: and To: header. you can add the following lines at the end of the file to add scores to such emails.
header FROM_SAME_AS_TO ALL=~/\nFrom: ([^\n]+)\nTo: \1/sm describe FROM_SAME_AS_TO From address is the same as To address. score FROM_SAME_AS_TO 2.0
Some spammers use an empty address for the Envelope From address (aka the Return Path header). Although this is legitimate for sending bounce messages, I prefer to give this kind of email a score.
header EMPTY_RETURN_PATH ALL =~ /<>/i describe EMPTY_RETURN_PATH empty address in the Return Path header. score EMPTY_RETURN_PATH 3.0
If you have configured OpenDMARC on your mail server, you can now add the following lines to add scores to emails that fail DMARC check.
header CUSTOM_DMARC_FAIL Authentication-Results =~ /dmarc=fail/ describe CUSTOM_DMARC_FAIL This email failed DMARC check score CUSTOM_DMARC_FAIL 3.0
The above code tells SpamAssassin to check if the Authentication-Results header contains the string “dmarc=fail”. If found, increase the score by 3.0.
Body Rules
You can tell SpamAssassin to increase the score of an email if a certain phrase is found in the body. For example, many spammers use the recipient’s email address in the first body line like below.
Hi xiao@linuxbabe.com Hello xiao@linuxbabe.com Dear xiao@linuxbabe.com
I don’t want to talk with people who doesn’t bother writing my name in the first line of email. So I created a rule in SpamAssassin to filter this kind of email.
body BE_POLITE /(hi|hello|dear) xiao\@linuxbabe\.com/i describe BE_POLITE This email doesn't use a proper name for the recipient score BE_POLITE 5.0
Regular expression in SpamAssassin is case-sensitive by default, you can add the i option at the end to make it case-insensitive.
Add Negative Scores
You can also add negative score to good emails, so there will be less false positives. For example, many of my blog readers ask me Linux questions and I don’t think spammers would include words like Debian, Ubuntu, Linux Mint in the email body, so I created the following rule.
body GOOD_EMAIL /(debian|ubuntu|linux mint|centos|red hat|RHEL|OpenSUSE|Fedora|Arch Linux|Raspberry Pi|Kali Linux)/i describe GOOD_EMAIL I don't think spammer would include these words in the email body. score GOOD_EMAIL -4.0
If the email body contains a Linux distro’s name, then add a negative score (-4.0).
There are some common phrases that is included in legitimate bounce messages, so I can add negatives scores to these email messages.
body BOUNCE_MSG /(Undelivered Mail Returned to Sender|Undeliverable|Auto-Reply|Automatic reply)/i
describe BOUNCE_MSG Undelivered mail notifications or auto-reply messages
score BOUNCE_MSG -1.5
Note that body rules also include the Subject as the first line of the body content.
Meta Rules
In addition to header and body rules, there’s also meta rules. Meta rules are combinations of other rules. You can create a meta rule that fires off when two or more other rules are true. For example, I occasionally receive emails saying that the sender wants to apply for a job and a resume is attached. I have never said on my website that I need to hire people. The attachment is used to spread virus. I created the following meta rule to filter this kind of email.
body __RESUME /(C.V|Resume)/i meta RESUME_VIRUS (__RESUME && __MIME_BASE64) describe RESUME_VIRUS The attachment contains virus. score RESUME_VIRUS 5.5
The first sub rule __RESUME tests if the email body contains the word C.V. or resume. The second sub rule __MIME_BASE64 is already defined in /usr/share/spamassassin/20_body_tests.cf file, as follows, so I don’t need to define it again in local.cf file. This rule tests if the email message includes a base64 attachment.
rawbody __MIME_BASE64 eval:check_for_mime('mime_base64_count')
describe __MIME_BASE64 Includes a base64 attachment
My meta rule RESUME_VIRUS will fire off when both of the sub rules are true, adding a 5.5 score to the email message. Note that sub rule often starts with double underscore, so it has no score in its own right.
Now you learned how to add score if a string is found. What if you want to add score when a string doesn’t exist in the email headers? Well, you can use the ! operator. For example, I have seen spammers using a single word in the From: address. I added the following lines to score this kind of email.
header __AT_IN_FROM From =~ /\@/ meta NO_AT_IN_FROM !__AT_IN_FROM score NO_AT_IN_FROM 4.0
The first line checks if the @ sign exists in the From: header. The second line defines a meta rule, which fires off when !__AT_IN_FROM is true. !__AT_IN_FROM rule is the opposite of the first header rule, which means when there’s no @ sign in the From: address, the meta rule fires off.
You can also add the following lines to check if a dot exists in the From: address.
header __DOT_IN_FROM From =~ /\./ meta NO_DOT_IN_FROM !__DOT_IN_FROM score NO_DOT_IN_FROM 4.0
Whitelist
You can use the whitelist_from parameter to add a particular email address or domain to your Spamassassin whitelist. For example, add the following two lines at the end of local.cf file.
whitelist_from xiao@linuxbabe.com whitelist_from *@canonical.com
A whitelisted sender has a -100 default score. They will still be tested by SpamAssassin rules, but it’s super hard for them to reach a 5.0 score.
Blacklist
To blacklist a sender, use the blacklist_from parameter, which has the same format as whitelist_from.
blacklist_from spam@example.com blacklist_from *@example.org
Checking Syntax and Restart
After saving the local.cf file. You should run the spamassassin command in lint mode to check if there’s any syntax errors.
sudo spamassassin --lint
Then restart SpamAssassin for the changes to take effect.
sudo systemctl restart spamassassin amavisd
SpamAssassin’s Builtin Whitelist
It’s worth mentioning that SpamAssassin ships with its own whitelist. There are several files under /usr/share/spamassassin/ directory that includes 60_whitelist in the filename. These files contain SpamAssassin’s builtin whitelist. For example, the 60_whitelist_spf.cf file contains a list of addresses which send mail that is often tagged (incorrectly) as spam.
Move Spam into the Junk Folder
I’m going to show you how to move spam to Junk folder with the Dovecot IMAP server and the sieve plugin. This method requires that inbound emails are delivered to the message store via the Dovecot “deliver” LDA (local delivery agent). If you can find the following text in /var/log/maillog file, then this requirement is satisfied.
postfix/lmtp
or
delivered via dovecot service
Run the following command install dovecot-pigeonhole package from CentOS/RHEL software repository.
sudo dnf install dovecot-pigeonhole
This package installs two configuration files under /etc/dovecot/conf.d/ directory: 90-sieve.conf and 90-sieve-extprograms.conf. Open the 15-lda.conf file.
sudo nano /etc/dovecot/conf.d/15-lda.conf
Add the sieve plugin to local delivery agent (LDA).
protocol lda {
# Space separated list of plugins to load (default is global mail_plugins).
mail_plugins = $mail_plugins sieve
}
Save and close the file. If you can find the 20-lmtp.conf file under /etc/dovecot/conf.d/ directory, then you should also enable the sieve plugin in that file like below.
protocol lmtp {
mail_plugins = quota sieve
}
Then open the 90-sieve.conf file.
sudo nano /etc/dovecot/conf.d/90-sieve.conf
Go to line 79 and add the following line, which tells Sieve to always execute the SpamToJunk.sieve script before any user specific scripts.
sieve_before = /var/mail/SpamToJunk.sieve
Save and close the file. Then create the sieve script.
sudo nano /var/mail/SpamToJunk.sieve
Add the following lines, which tells Dovecot to move any email messages with the X-Spam-Flag: YES header into Junk folder.
require "fileinto";
if header :contains "X-Spam-Flag" "YES"
{
fileinto "Junk";
stop;
}
Save and close the file. We can compile this script, so it will run faster.
sudo sievec /var/mail/SpamToJunk.sieve
Now there is a binary file saved as /var/mail/SpamToJunk.svbin. Edit the 10-mail.conf file.
/etc/dovecot/conf.d/10-mail.conf
Add the following line in the file, so that individual user’s sieve scripts can be stored in his/her home directory.
mail_home = /var/vmail/%d/%n
Finally, restart dovecot for the changes to take effect.
sudo systemctl restart dovecot
Set Message Maximum Size
By default, SpamAssassin does not check messages with attachments larger than 500KB, as indicated by the following line in the /var/log/mail.log file.
spamc[18922]: skipped message, greater than max message size (512000 bytes)
The default max-size is set to 512000 (bytes). A high value could increase server load, but I think the default size is a little bit small. To increase the max-size, edit /etc/sysconfig/spamass-milter file and find the following line.
EXTRA_FLAGS="-m -r 8 -R SPAM_ARE_NOT_ALLOWED_HERE -i 127.0.0.1 -g sa-milt"
Add the -- --max-size=5120000 option at the end.
EXTRA_FLAGS="-m -r 8 -R SPAM_ARE_NOT_ALLOWED_HERE -i 127.0.0.1 -g sa-milt -- --max-size=5120000"
The empty -- option tells spamass-milter to pass all remaining options to spamc, which understands the --max-size option. I increased the size to 5000KB. Save and close the file. Then restart spamass-milter.
sudo systemctl restart spamass-milter
How to Configure Individual User Preferences
You may want to set custom rules for emails sent to a specific address on the mail server. I like this feature very much. I have a contact email address for this blog, which is only used for keeping contact with readers. I don’t use the contact email address elsewhere, so I can create special spam-filtering rules that apply only to this contact email address.
First, edit the SpamAssassin main configuration file.
sudo nano /etc/mail/spamassassin/local.cf
Add the following line to allow user rules.
allow_user_rules 1
Save and close the file. Next, edit the SpamAssassin environment file.
sudo nano /etc/sysconfig/spamassassin
Find the following line.
SPAMDOPTIONS="-c -m5 -H --razor-home-dir='/var/lib/razor/' --razor-log-file='sys-syslog'"
We need to add several extra options.
SPAMDOPTIONS="-c -m5 -H --razor-home-dir='/var/lib/razor/' --razor-log-file='sys-syslog' --nouser-config --virtual-config-dir=/var/vmail/%d/%l/spamassassin --username=vmail"
Where:
--nouser-config: disable per-user configuration file for local Unix users.--virtual-config-dir: specify the per-user configuration directory for virtual users. The%dplaceholder represents the domain part of email address and%lrepresents the local part of email address.--username: run spamd as the vmail user.
Save and close the file. Then restart SpamAssassin.
sudo systemctl restart spamassassin
By default, spamass-milter doesn’t pass the recipient address to SpamAssassin. We need to make it send the full email address to SpamAssassin. Edit the spamass-milter configuration file.
sudo nano /etc/sysconfig/spamass-milter
Add the following option.
-e yourdomain.com -u sa-milt
Like this:
EXTRA_FLAGS="-e yourdomain.com -u sa-milt -m -r 8 -R SPAM_ARE_NOT_ALLOWED_HERE -i 127.0.0.1 -g sa-milt -- --max-size=5120000"
The -e option will make spamass-milter pass the full email address to SpamAssassin. Replace yourdomain.com with your real domain name. Save and close the file. Then restart spamass-milter.
sudo systemctl restart spamass-milter
Now send an email from Gmail, Hotmail, etc. to your domain email address. You will find the spamassassin directory is automatically created under /var/vmail/yourdomain.com/username/ directory.
cd /var/vmail/yourdomain.com/username/spamassassin/
You can use a command-line text editor to create the per-user preference file here. This file must be named as user_prefs.
sudo nano user_prefs
You can add custom rules in this file just as you would do in the /etc/spamassassin/local.cf file.
For instance, I found many spammers end their email body with an unsubscribe link to let you remove future contact. I didn’t subscribe to their spam and I don’t think the unsubscribe link will remove my email address from their contact database. So I use SpamAssassin to score this kind of email. The following rule adds 3.0 score to emails containing the word “unsubscribe” or its variations in the body. (I don’t use the contact email address of this blog to subscribe to anything online.)
body SUBSCRIPTION_SPAM /(unsubscribe|u n s u b s c r i b e|Un-subscribe)/i describe SUBSCRIPTION_SPAM I didn't subscribe to your spam. score SUBSCRIPTION_SPAM 3.0
Sometimes the email body doesn’t contain the word “unsubscribe”, but the there’s a List-Unsubscribe header, which means the spammer added my contact email address to their mailing list without my consent. I can score this type of email too, with the following rule.
header LIST_UNSUBSCRIBE ALL =~ /List-Unsubscribe/i describe LIST_UNSUBSCRIBE I didn't join your mailing list. score LIST_UNSUBSCRIBE 2.0
I created a Mailjet account with a different email address. Some spammers assume that I used my contact email address to create Mailjet account, so they try to impersonate Mailjet customer service to lure me into typing my password at a fake Mailjet login page. I can score this kind of email like below.
header MAILJET_IMPOSTER From =~ /mailjet/i describe MAILJET_IMPOSTER I don't have a mailjet account for this email address. score MAILJET_IMPOSTER 2.5
The above lines check if the From: header contains the word mailjet. If found, give it a 2.5 score.
I occasionally receive emails from Chinese spammers whose From: domain name has no vowel letters (a, e, i, o, u). The spammer used the cdjcbzclyxgs.xyz domain name. It is nearly impossible for a normal person/entity to use domain names without vowel letters, considering that many top level domains have already included vowel letters (.com, .net, .org, .co, .io, .shop, .dev, etc), so I give this kind of email a very high score like below. The default score is 0.5.
score FROM_DOMAIN_NOVOWEL 4.0
Some spam emails use many images in the body but contains very little text. The default score for this kind of email is 1.9, but I prefer to set a high score for my contact email address.
score HTML_IMAGE_RATIO_02 4.0
I also received a spam email with my email address in the subject, so I can add a high score to it.
header SUBJECT_SPAM Subject =~ /xiao\@linuxbabe.com/i describe SUBJECT_SPAM Subject contains my email address. score SUBJECT_SPAM 4.0
Some spammers use BCC (Blind Carbon Copy) to hide other recipients. I don’t want to receive such email. So I made the following rule. If my domain name is not in the To: header, add 3.0 to the email.
header __DOMAIN_IN_TO To =~ /linuxbabe.com/ meta DOMAIN_NOT_IN_TO !__DOMAIN_IN_TO score DOMAIN_NOT_IN_TO 3.0
After adding custom rules, close the file and run the following command to check syntax. Silent output means there’s no syntax error.
sudo spamassassin --lint
Finally, restart SpamAssassin for the changes to take effect.
sudo systemctl restart spamassassin
Now you can test the user preferences by sending test emails from other email services to your own domain email address.
Reject or Bounce
If a receiving SMTP server determines during the SMTP conversation that it will not accept the message, it rejects the message. Sometimes the SMTP server accepts a message and later discovers that it cannot be delivered, perhaps the intended recipient doesn’t exist or there is a problem in the final delivery. In this case, the SMTP server that has accepted the message bounces it back to the original sender by sending an error report, usually including the reason the original message could not be delivered.
You should not bounce spam, because the email address in the Return-path: header or From: header probably doesn’t exist or is an innocent person’s email address, so the bounce message will probably go to an innocent person’s email address, creating the backscatter problem. Instead of bouncing the spam, you should reject spam during the SMTP dialog, before the email is accepted. This article didn’t show you bouncing a spam message. You should remember this rule in case you are going to create spam-filter rules by yourself. If in doubt, test your spam-filtering rules to see if it’s going to create bounce messages.
URIBL_BLOCKED
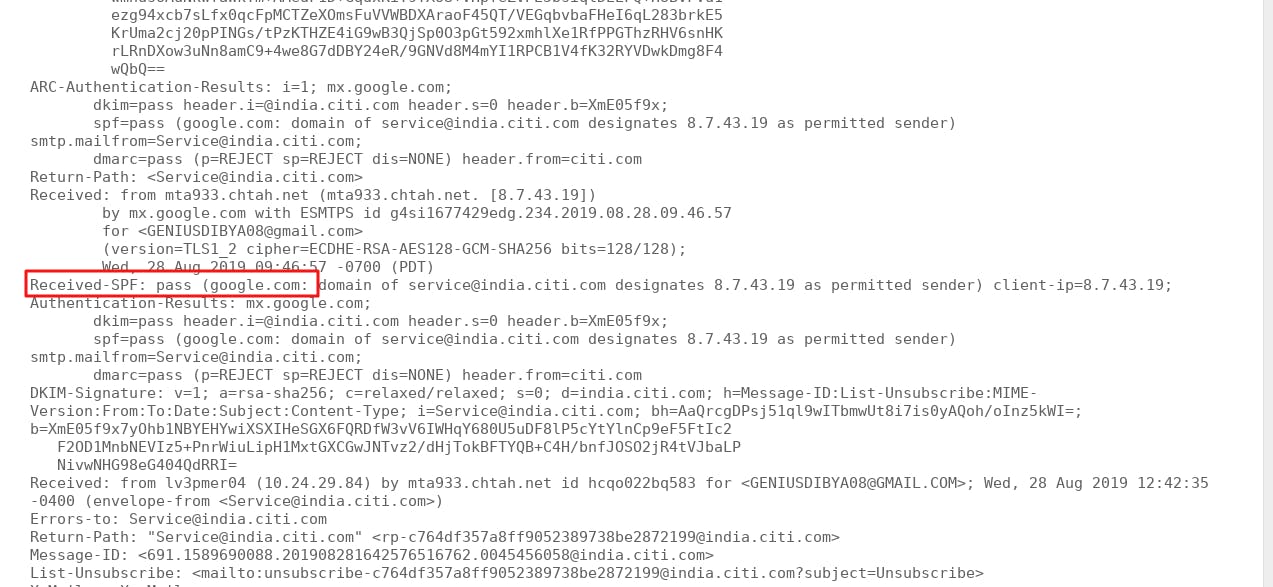
By default, SpamAssassin enables URIBL rule, which checks if an email message contains links that are identified as spam by URIBL. This is a very effective anti-spam measurement. However, you might be blocked from querying URIBL. Check the raw email headers of an inbound email message, find the X-Spam-Status header.
X-Spam-Status: No, score=-92.2 required=5.0 tests=DATING_SPAM,DKIM_SIGNED, DKIM_VALID,HTML_FONT_LOW_CONTRAST,HTML_MESSAGE,SPF_PASS, SUBSCRIPTION_SPAM,UNPARSEABLE_RELAY,URIBL_BLOCKED,USER_IN_WHITELIST autolearn=no autolearn_force=no version=3.4.2
If you can find URIBL_BLOCKED in this header, that means you are blocked from querying URIBL. Most of the time it’s because you are not using your own local DNS resolver. You can run the following command on your mail server to test which DNS server you are using to query URIBL.
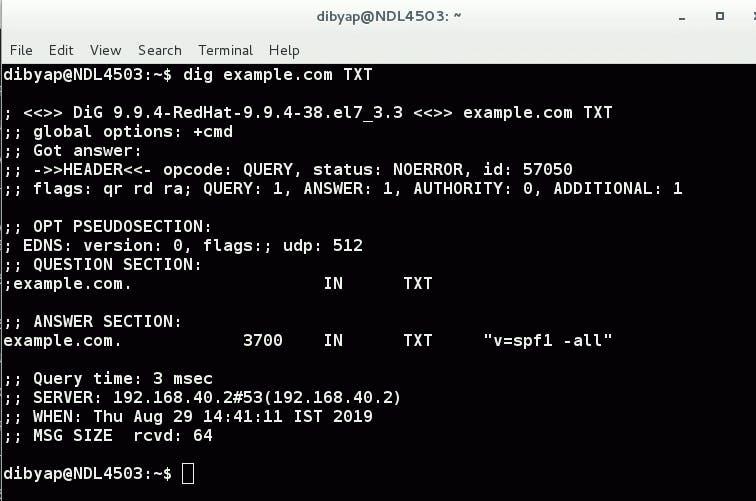
host -tTXT 2.0.0.127.multi.uribl.com
Sample output:
2.0.0.127.multi.uribl.com descriptive text "127.0.0.1 -> Query Refused. See http://uribl.com/refused.shtml for more information [Your DNS IP: xx.xx.xx.xx]"
To fix this error, you need to run your own local DNS resolver on your mail server.
Once your local DNS resolver is up and running, test URIBL again.
host -tTXT 2.0.0.127.multi.uribl.com
If you see the following output, it means you are now allowed to query URIBL.
2.0.0.127.multi.uribl.com descriptive text "permanent testpoint"
From here on out, inbound email messages won’t have the URIBL_BLOCKED tag in the X-Spam-Status header.
Other Tidbits
SpamAssassin 4.0 includes a HashBL plugin, which can check if a Bitcoin address in the email body has been used by scammers. And there’s also a new plugin called “Ole Macro” that can check if an email contains an Office attachment with a macro. This plugin would try to detect if the attched macro is malicious or not.
Wrapping Up
I hope this tutorial helped you use Postifix and SpamAssassin to filter spam. As always, if you found this post useful, then subscribe to our free newsletter to get more tips and tricks. Take care 🙂
how to test spamassasin
vim /usr/share/doc/spamassassin/sample-spam-01.txt
and copi the source of the email
spamassassin -t -D razor2 < /usr/share/doc/spamassassin/sample-spam-01.txt